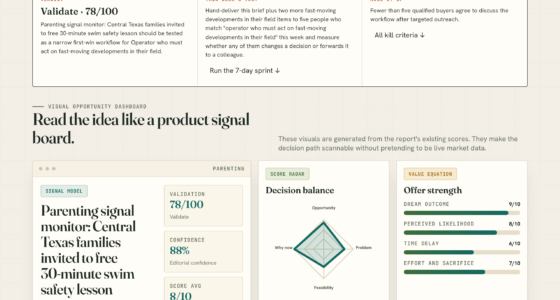
TL;DR
Jamesob has published a detailed guide for individuals to run state-of-the-art large language models on local hardware. This development aims to democratize access to advanced AI models, reducing reliance on cloud services.
Jamesob has released a comprehensive guide that details how to run state-of-the-art large language models (SOTA LLMs) on local hardware. This guide aims to make advanced AI models more accessible outside of cloud-based environments, potentially impacting researchers, developers, and hobbyists. The publication is significant as it lowers barriers to entry for utilizing cutting-edge AI technology.
The guide, available publicly online, covers hardware requirements, setup procedures, and optimization tips for running SOTA LLMs such as GPT-4, LLaMA, and PaLM locally. Jamesob emphasizes that with recent advancements in model efficiency and open-source releases, it is now feasible for individuals with high-performance hardware to operate these models without relying on cloud services. The guide includes detailed instructions on installing necessary software, configuring environments, and managing computational resources.
According to Jamesob, the process involves using optimized versions of model weights, leveraging hardware accelerators like GPUs or TPUs, and employing open-source frameworks such as Hugging Face Transformers or custom implementations. The guide also discusses potential limitations, including hardware constraints and performance trade-offs, and provides troubleshooting advice for common issues encountered during setup.
Impact of Democratizing Access to SOTA LLMs
This development is noteworthy because it could democratize access to advanced AI models, enabling research institutions, startups, and individual developers to experiment and deploy powerful language models without incurring high cloud costs. It challenges the conventional reliance on cloud providers and could accelerate innovation in AI applications. However, it also raises questions about hardware accessibility and the environmental impact of running large models locally.

AI Systems Performance Engineering: Optimizing Model Training and Inference Workloads with GPUs, CUDA, and PyTorch
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Recent Trends in Open-Source AI and Local Deployment
Over the past year, there has been a surge in open-source releases of large language models, including LLaMA, Falcon, and OpenAI’s smaller models. Advances in model compression, quantization, and hardware acceleration have made local deployment increasingly feasible. Previously, running SOTA LLMs required significant infrastructure, often limiting access to large organizations. Now, efforts like Jamesob’s guide are part of a broader movement toward decentralizing AI development and use.
This guide builds on prior initiatives that have aimed to simplify setup processes, but it stands out by providing detailed, practical instructions tailored for the latest models and hardware setups. The timing aligns with the growing interest in privacy-preserving AI and cost-effective deployment options.
“This guide aims to lower the barriers for anyone interested in running cutting-edge language models on their own hardware.”
— Jamesob

Local LLM Inference Optimization: A Comprehensive Guide to Quantization, Hardware Acceleration, and Efficient Private AI Deployment
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Limitations of Hardware and Model Accessibility
While the guide provides a clear pathway for many users, it is not yet confirmed how many individuals can practically implement these setups given hardware constraints. High-performance GPUs or TPUs remain expensive and may not be accessible to all. Additionally, some models require significant computational resources, which could limit deployment to well-funded entities. The environmental impact of running large models locally is also an area of ongoing debate.

Transformers Studio Series Leader Class The The Movie Soundwave 6.5-Inch Converting Action Figure, Robot Toys for Ages 8+
THE TRANSFORMERS: THE MOVIE SOUNDWAVE: This Transformers Studio Series Soundwave figure features movie-inspired deco and details
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Next Steps for Broader Adoption and Community Feedback
Following the release of the guide, the community is expected to experiment with the outlined procedures, potentially leading to further refinements and shared best practices. Developers may also work on optimizing models for even lower hardware requirements, broadening accessibility. Jamesob and others might release updates or new tutorials based on user feedback, while industry stakeholders observe how local deployment impacts cloud service demand.

Hands-On LLM Serving and Optimization: Hosting LLMs at Scale
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Key Questions
What hardware do I need to run SOTA LLMs locally?
Typically, a high-performance GPU such as an NVIDIA A100, H100, or equivalent is recommended, along with sufficient RAM and storage. The exact requirements depend on the model size and optimization techniques used.
Are there open-source models available for this purpose?
Yes, models like LLaMA, Falcon, and smaller versions of GPT are available open-source and are discussed in Jamesob’s guide for local deployment.
Does running models locally reduce costs compared to cloud services?
In many cases, yes, especially for repeated use or large-scale deployment, though initial hardware investment can be significant. Ongoing power and maintenance costs also factor in.
What are the environmental implications of local deployment?
Running large models locally consumes substantial energy, which raises environmental concerns. Balancing local deployment with energy efficiency remains an ongoing challenge.
Source: hn